🕵️♂️ Deep research: How it works and how to build it
✋ Before we dive in...
If you're keen to understand how deep research works, you can play with my Python implementation here or install it with pip install deep-researcher. It produces detailed reports with one CLI command:
deep-researcher --query "Write about Plato's life and works"
🙏 A New Hope
Back in 2023, AutoGPT dropped — and it felt like magic ✨. It was the first major example we had of an AI agent that could plan and execute complex tasks autonomously. Given a high-level goal, it would break problems down into sub-tasks and use tools in a continuous loop to solve them. It could google stuff, open websites, write files, and even reflect on its own performance.
But... it also kinda sucked.
- It got stuck in loops
- It forgot what it was doing mid-way
- It hallucinated confidently
- It burned through tokens (and your wallet 💸)
🧠 The LLM As The "Central Brain"
Despite these limitations, AutoGPT and similar prototypes proved the concept of autonomous agentic AI. They established a basic architecture that many later systems would build on: an LLM as the central “brain”.
Research from this period introduced techniques like ReAct (Reason + Act), which had the model interweave reasoning statements with tool calls (e.g. “Thought: ...; Action: ...”), rather than issuing commands without explanation. This helped create an internal chain-of-thought and reduced obvious failures. Other experiments introduced forms of self-reflection (having the model critique its own past actions) to prevent it from getting stuck in loops.
The early agent systems laid the groundwork by identifying what was needed: the ability to decompose tasks, remember intermediate results, leverage external knowledge sources, and safely remain goal-directed.
🤔 What Was Missing
These early recursive agents needed 4 critical upgrades to work well:
-
Larger context windows: To remember the original task as well as historical actions and findings. GPT-3.5 originally had a context window of only 4k tokens vs 128k for GPT-4o and 200k for o3-mini.
-
Multi-modal capability: To enable agents to interpret and interact with more resources - especially images.
-
A stronger ecosystem of tools: The ability to use browsers, search the web, execute code in a sandboxed environment, access local files and APIs etc. The open source community has seen an explosion of tooling in the last year, for example:
- Browser Use to control browsers
- Tavily, Exa, Firecrawl and Crawl4AI for web search and retrieval
- E2B for executing code in a sandbox
- The MCP protocol from Anthropic
-
Better tool selection capability: To actually pick the right tool for each task without getting stuck in loops, hallucinating or veering off-topic. GPT-4o, 4o-mini and o3-mini introduce massive improvements in tool-selection. This leaderboard is my favourite reference on this - what's incredible is how performant 4o-mini is despite being 10-50x cheaper (and substantially faster) than similarly ranked models.
🚀 Fast Forward to Now...
Huge improvements across all three fronts have led to the rise of:
- Deep research agents: OpenAI, Google, Perplexity all offer their own versions of deep research.
- Open-source versions: Hugging Face, LangChain and even my own version
- Other agentic apps: Like Manus AI for general tasks, Convergence for productivity, Roo Code for coding. These combine deep research logic with broader, multi-tool capabilities — think coding, file analysis, PDFs, browsing, image understanding, etc.
🤖 How Deep Research Works
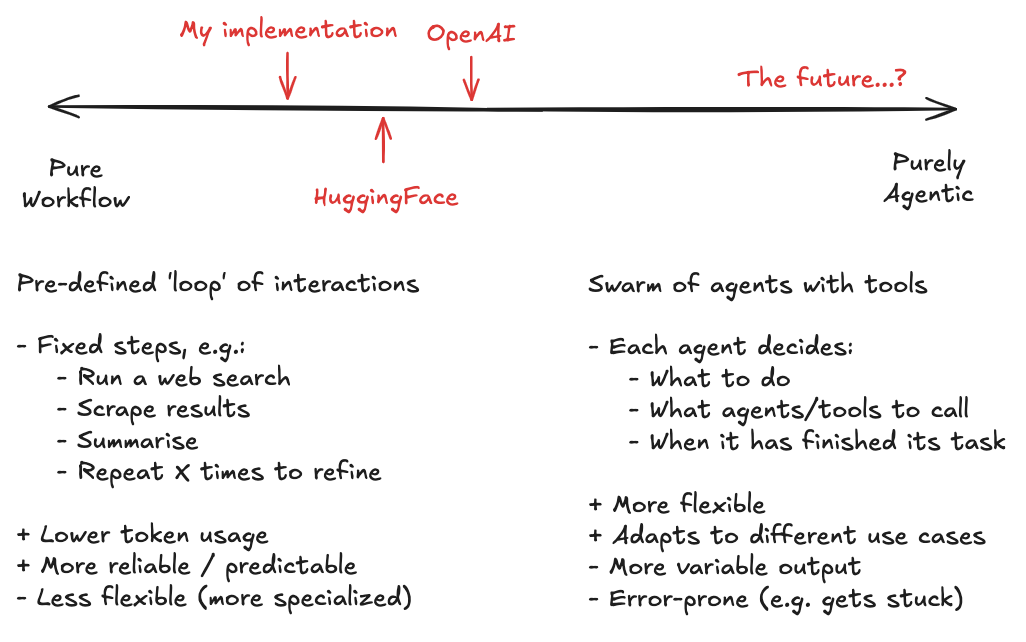
You can think of two paradigms for building AI apps that sit on opposite ends of a spectrum.
-
Workflow tools follow a fixed flow often in a loop
E.g.Think → Search → Read → Repeat → Summarize. -
Purely agentic tools go wild with autonomy
E.g. one or many agents with defined roles autonomously deciding what tools to use, what to do next, who to pass tasks to, and when they've finished their task. This could mimic human teams - a supervisor, line-manager, teams of analysts working on sub-tasks.
Most real-world implementations sit somewhere in between. Bear in mind that Deep Research is just one use-case (i.e. producing long reports), but similar frameworks with a wider set of tooling can cater to broader use-cases. For example, Manus AI demonstrates what you can achieve with a set of agents wrapped around Claude and Qwen with access to 29 tools. Under the hood, all of these apps are using fairly fixed workflows to minimise token usage and improve reliability.
🏢 OpenAI’s Approach (Deep Research)
- Based on a smart model (o3, not yet available via API) fine-tuned for multi-step reasoning and tool use
- Uses an internal framework to plan → search → read → think → write
- Utilizes their in-house browser tool (Operator) to interact with the web
- Has the ability to backtrack to avoid getting stuck in loops
- Outputs full reports with citations and source traceability
- Achieves state-of-the-art results on real-world benchmarks (GAIA, etc.)
- But: it's proprietary, compute-intensive, and gated to higher-tier users
🐧 Open Source Agents
Most open-source approaches:
- Stick with workflow-first logic (to keep things predictable and cheap)
- Can achieve surprisingly good performance even with open models like DeepSeek
- Are often faster and cheaper to run — and highly customizable.
But they don’t yet have:
- Vision support (unless you bolt it on)
- Sophisticated browsers like OpenAI’s Operator
- As much safety and hallucination mitigation
Hugging Face's implementation uses code-based agents: instead of saying “search for X using the search tool" (in a JSON output), the model writes Python code to do it. This might sound odd at first, but it has some powerful advantages:
- Code can express more complex logic than a single / sequential set of tool calls
- Code is more concise - e.g. it can write code to run a bunch of tools in parallel, which lowers token usage
- LLMs are good at writing code and can self-debug if there are errors
A recent paper showed that letting the agent express complex action sequences in code can make the whole process more efficient and reliable. The Hugging Face open deep research project implemented this idea and saw a big boost in performance: their accuracy on one benchmark jumped from 33% to 55% simply by switching from JSON-style actions to code-style actions (with the same underlying model and tasks).
🧪 The QX Labs Implementation
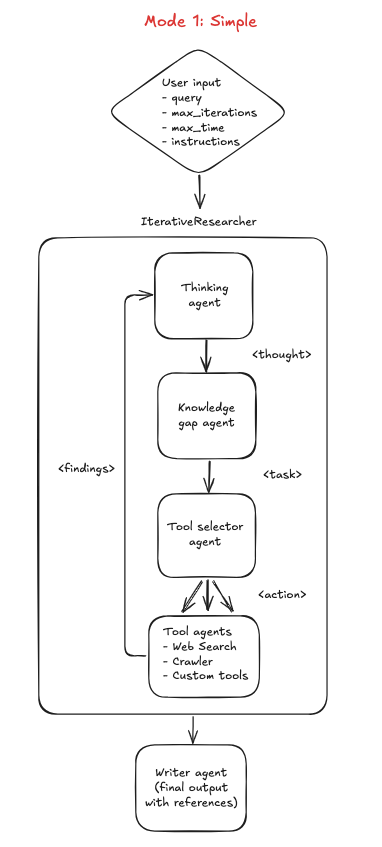
For illustration, let me break down how my implementation works.
TL;DR: It leans workflow-heavy but with autonomy on tool selection and async execution for scale.
- Carries out initial research on the query to understand the topic
- Splits the research topic into sub-topics and sub-sections
- Iteratively runs research on each sub-topic - this is done in async/parallel to maximise speed
- Consolidates all findings into a single report with references
- (Optional) Includes a full trace of the workflow and agent calls in OpenAI's trace system
It has 2 modes:
-
Simple Mode
Runs the iterative researcher (Step 3 above) on the full query in one go.
Great for fast answers on narrower topics. -
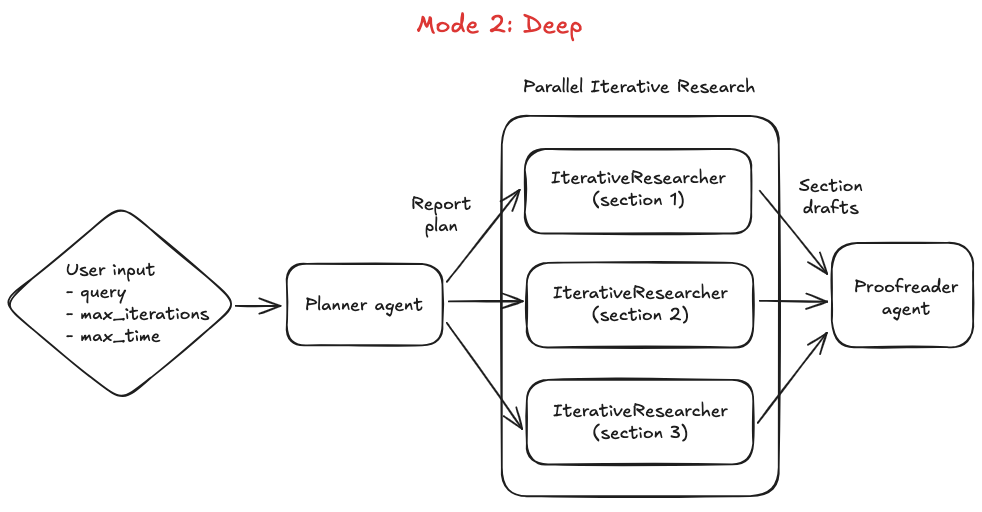
Deep Mode
Runs the planning phase (Step 1+2 above) then spawns concurrent researchers for each sub-topic.
Ideal for multi-dimensional or expansive research questions.
💡 Interesting Findings
-
gpt-4o-mini is 🔥 for this use case
- Matches o3-mini on tool-use benchmarks
- Faster + cheaper
- You don’t need the full GPT-4o brain since deep research relies more on retrieved content than parametric knowledge
-
LLMs suck at following word count instructions
- Better to use heuristics they’ve seen before like:
- “Length of a tweet”
- “A few paragraphs”
- “2 pages of text”
- Better to use heuristics they’ve seen before like:
-
Most LLMs cap at ~2,000 words of output even though they can in theory output thousands more tokens
- Why? Because they weren’t trained to write 50-page documents
- Want longer reports?
- Use a streaming writer pattern that chains LLM outputs (like this approach)
- Or chunk by section and concatenate intelligently (watch out for repetition)